
一、Mysql数据的存放路径
mysql默认将数据保存在/var/lib/mysql/database_name路径下,路径下面有三种文件
.opt:存储当前数据库的默认字符集和字符校验规则
.frm:mysql的每张表对应一个.frm文件,用来保存每张表的元数据信息,主要包含每张表的表结构定义
.ibd:新版本的mysql,每张表的数据都保存在一个独立的ibd文件中,这个文件也称为独占表空间文件
二、表空间的文件结构
表空间由段、区、页、行组成,InnoDB存储引擎的大致结构:
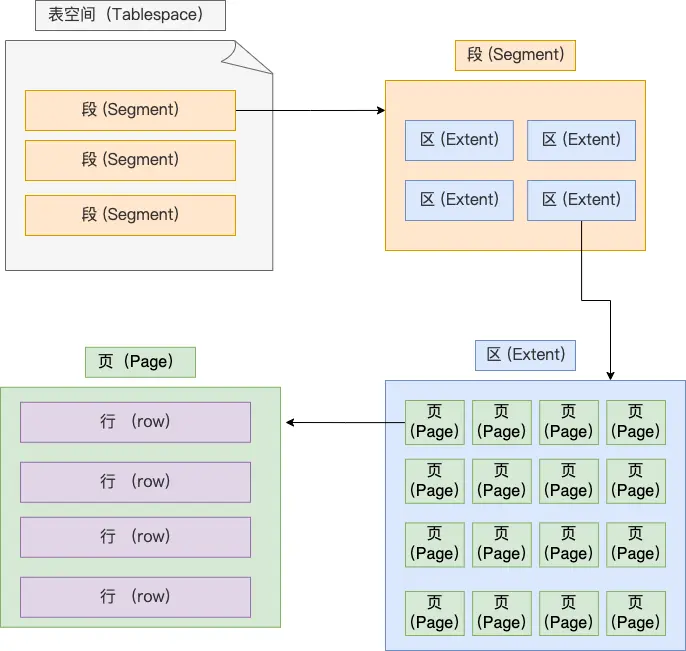
1、行
mysql数据库中的记录都是以行进行存放的,每行记录根据不同的行格式,有不同的存储结构
2、页
数据的存储以行为单位,但是数据的读写是以页为单位的,否则一次读取(对应一次IO操作,只能读取一行数据,效率过低),也就是说mysql每次读取都是直接读一整页到内存里面,一页的大小是默认是16KB。
InnoDB中的页有多种类型,包括数据页、undo日志页、溢出页等,数据表中的行记录是用数据页来管理的。
mysql中B+树作为索引的数据结构,就是用的数据页作为B+树的节点。
3、区
为什么有了页还要有区?
首先InnoDB用B+树来组织数据,B+树的每一层都是通过双向链表连接的,如果以页为单位来分配,意味着每一层将产生大量的页(因为页的存储容量较小),其次大量的页物理位置是不相邻的,因此在遍历链表的过程中将产生大量的磁盘随机IO,效率极低。
因此,InnoDB在认为数据量较大时,给索引分配空间时,就不再以页为单位,而是以区为单位,一个区是1MB,对应连续的64个页,这样页与页之间的物理位置相邻,就可以使用顺序IO,提升效率。
4、段
表空间是由各个段组成的,段是由多个区组成的。
段一般分为数据段、索引段、回滚段等。
数据段:存放B+树叶子节点的区的集合(我理解是主键索引)
索引段:存放B+树非叶子节点的区的集合(我理解是二级索引)
回滚段:存放的是回滚数据的区的集合
三、InnoDB的行格式
行格式(row_format),就是一条记录的存储结构。
较早的行格式Redundant已经废弃不用,取而代之的是Compact,一种紧凑的行格式,是为了让一个数据页里面可以存放更多的行记录。
Dynamic和Compressed也是两个紧凑型的行格式,mysql新版本(5.7之后)默认Dynamic行格式,与Compact相似。
下面讲述的是Compact行格式
Compact行格式
compact行格式下,一条记录分为:记录的额外信息与记录的真实数据两个部分
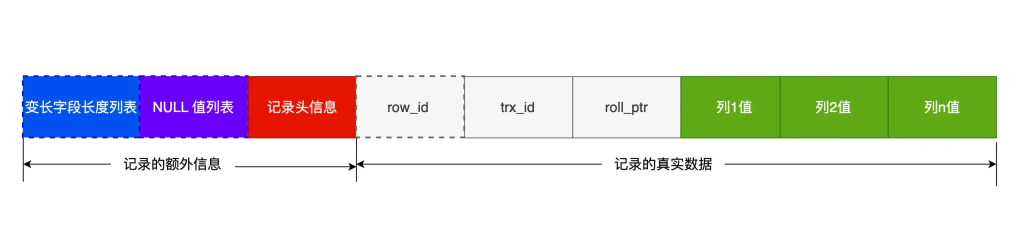
1、记录的额外信息
记录的额外信息包含三个部分:变长字段长度列表,NULL值列表,记录头信息
1.变长字段长度列表
varchar是变长的,所以必须把数据的长度存储起来。存储到边长字段长度列表里,相当于当新建一个varchar列的时候,mysql新建一个列,用来记录varchar列的真实长度。如果表里面没有变长字段,那么就不需要这个变长字段长度列表。
InnoDB中varchar最大长度是65535,也就是说最多可能要用两个字节来存储varchar列的长度,InnoDB对于varchar(255)及以下,用一个字节来存储,对于varchar(255)以上,采用2个字节来存储。
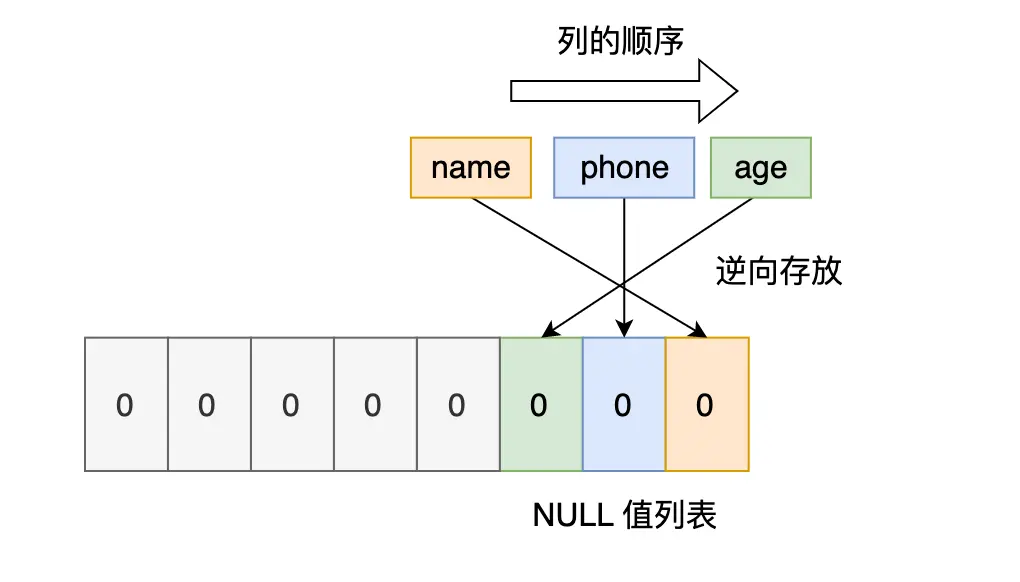
变长字段长度列表的数据放在变长字段长度列表部分(compact行格式的蓝色部分),它的顺序与列的顺序是相反的,原因是这样靠前的记录与它的变长字段长度列表更有可能同时在一个CPU Cache Line中,可以提高CPU Cache Line的命中率。
同理,下面的NULL值列表也是逆序存放的。
2.NULL值列表
如果表中null值,真的存储起来,会比较浪费空间,所以InnoDB用一个bitmap放在null值列表里面,用来标记当前这一行数据,它对应的可以为null的列的值是否的确是null,如果是null,那么对应的bit位是1,否则对应的bit位是0。
那么1个字节有8个bit,所以能标记8列,如果一张表有超过8列的数据可以为null,则需要2个bit,以此类推,如果一张表里面没有可以为null的值,就不会有null值列表,也就不会占用任何字节。
null值列表和变长字段列表一样,都是和列的顺序反着来的,如下面的例子
3.记录头信息
delete_mask:标记此条数据是否被删除。所以执行删除数据的时候,数据并不会真的被删除,只是将delete_mask置为1;
next_record:下一条记录的位置。记录与记录之间是通过链表组织的。next_record指向的是下一条记录的记录头信息与记录真实数据之间的位置。这样做的好处是,往左边读就是记录头信息,往右边读就是真实数据。
记录头中信息很多,上面两个是比较重要的。
2、记录的真实数据
记录的真实数据包含两部分:
三个隐藏字段:row_id,trx_id,roll_pointer;另一部分才是用户定义的列;
row_id:如果建表的时候,没有指定主键或者唯一约束列(必须是not null unique,单独的unique不行,因为存在空值,导致无法唯一识别每一行记录),那么InnoDB就会生成row_id列,作为主键索引。row_id列占用6个字节。
trx_id:事务id,标识是由哪个事务生成的,trx_id是必需的,占用6个字节。
roll_pointer:这条记录上一个版本的指针。roll_pointer是必需的,占用7个字节。
四、额外的问题
1、varchar(n)中n的最大取值
mysql规定,除了text、blobs这种大对象类型之外,其他所有列(不包括隐藏列和记录头信息)占用的字节加起来不能超过65535个字节。
也就是说:变长字段长度列表 + null值列表 + 用户自定义的列 < 65535字节
假设建立一张表,只有一个varchar(65535)类型的字段,并且允许null值,将创建失败。
对于varchar(n),n > 255,那么变长字段长度列表就会占用2字节,另外允许null值,所以占用1字节,所以实际上留给用户自定义列的总可用字节数在65532字节。
下面这条语句创建表会成功:
CREATE TABLE test (
`name` VARCHAR(65532) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;显示
CREATE TABLE test (
`name` VARCHAR(65532) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT
> OK
> 时间: 0.077s如果设定为not null,则可以创建到65533。
如果设定为null,只能到65532,65533会报错。
CREATE TABLE test (
`name` VARCHAR(65533) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT
> 1118 - Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
> 时间: 0.001s2、行溢出后,InnoDB的处理
InnoDB一个页大小一般是16KB,也就是16*1024=16384字节,而刚刚计算过一个varchar就可以占用65533字节,另外对于text和blob类型的大对象,可能存储更多的数据,这时一个页中将存不了一条记录,这时候将发生行溢出,溢出的数据将存储到另外的溢出页中。
当发生行溢出时,在记录的真实数据处,只会保存该列的一部分数据,而把剩余的数据放在溢出页中,然后真实数据处用20字节的存储指向溢出页的地址,从而找到剩余数据所在页的地址。
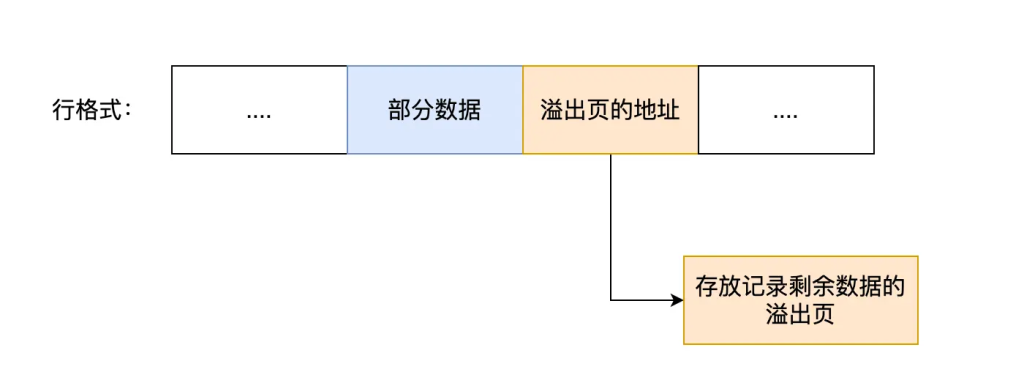
那么InnoDB读取数据的时候,如何知道行发生了数据页溢出呢?是通过记录头中有个info_bits字段,其中有一个bit标记了行是否发生了溢出。







