
新年快乐! | 国会山上空的烟花,渥太华,加拿大 (© naibank/Getty Images) – 2024/12/31
今天是2024年的最后一天。新旧之年交替的夜晚被称为跨年夜,世界各地通常会举办烟火表演,一些地区则通过宗教和文化仪式迎接新年。许多国家还会用象征繁荣、长寿和好运的食物来迎接新年。在中国,人们会与亲朋好友聚在一起进行各种“除夕夜”活动,如旅行、听除夕音乐会或享用丰盛的除夕晚餐。
磁盘读写的最小单位是扇区,扇区只有512B大小,操作系统一次会读取多个扇区,所以操作系统最小的读写单位是块(block)。Linux中的块大小是4KB,也就是一次磁盘IO会读写8个扇区。
数据库的索引也是保存到磁盘中的,因此当通过索引查找数据的时候,需要先从磁盘将索引加载到内存,再通过索引,从磁盘中找到数据,然后读入到内存,也就是查询过程中会发生多次磁盘IO,而磁盘IO次数越多,所消耗的时间也越多。
另外作为数据库,很可能会出现范围查找的业务需求。
所以mysql中索引的数据结构希望:
- 从效率的角度出发:希望尽可能少的磁盘IO
- 从业务的角度出发:要能高效地查找某条记录,也要能高效地执行范围查找
B+Tree
B+Tree是一种多叉树,它的叶子节点才存放数据,非叶子节点只存放索引;
数据在叶子节点中是按照主键顺序存放的。
每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中包含了所有的索引值信息,并且每一个叶子节点都有两个指针指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的B+Tree如图所示(以下图片中未体现双向链表,实际是双向链表)
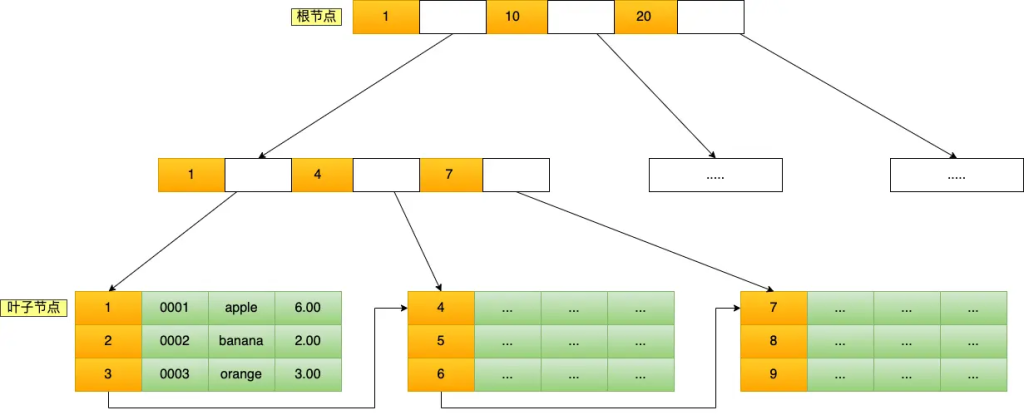
由于数据库的索引和数据都是存储在硬盘的,可以认为读取一个节点对应一次磁盘IO操作。
B+Tree存储千万级别的数据仅需要3-4层高度,可以最大程度的减少磁盘IO。
1、B+Tree vs BTree
B+Tree的节点更小:B+Tree只在叶子节点存储数据,而B树的非叶子节点也要存储数据,所以B+Tree单个节点的数据大小更小,一次磁盘IO能加载更多的节点到内存中。
B+树支持范围查找:因为B+树的最底层也就是叶子节点采用的是双向链表,所以支持范围查找,而B树不能支持范围查找。
2、B+Tree vs 二叉树
B+Tree的树高度一般维持在3-4层左右,也就是磁盘IO3-4次就可以支持千万量级的数据,而二叉树的搜索复杂度是O(logN),千万量级的数据,可能需要20次甚至以上的磁盘IO,效率远低于B+Tree。
3、B+Tree vs Hash
Hash只适合等值查询,不适合范围查询。








评论