
冰雪倒影和积雪覆盖的群峰 | 布莱德湖,斯洛文尼亚 (© Kesu01/Getty Images) – 2024/12/27
斯洛文尼亚的布莱德湖在夏季备受关注,而在冬季,这里的一切都放慢了脚步。湖水碧绿,色调柔和,湖心岛上的古朴教堂宛如从冬季童话中走出的一般,正如今日图片所示。这座长1.3英里的湖泊,被积雪覆盖的朱利安阿尔卑斯山环绕,形成于大约14,000年前的冰川与地质活动。布莱德岛上最早的定居迹象可追溯至新石器时代(公元前10,000年至公元前3,000年)。此外,考古学家在这里还发现了公元9世纪的中世纪早期墓地。如今,这里坐落着圣母升天教堂,其现有建筑形式建于17世纪末,游客们会在这里敲响“许愿钟”以祈求好运。当你来到这里时,不要因为惧怕寒冷就只待在室内。围绕湖边散步,乘坐传统的手划船“普莱特纳”前往布莱德岛,或前往布莱德城堡俯瞰小镇全貌。如果喜欢冒险,湖附近还有许多滑雪场可供体验。在离开之前,不妨犒劳一下自己,去尝尝布莱德奶油蛋糕,就会明白它为什么能成为当地的美食符号。
本文内容根据索引常见面试题内容结合自己理解整理得到。
mysql中的数据和索引都是存储在硬盘中,读取的速度十分缓慢。
文章中的内容如无指定存储引擎,均是指InnoDB引擎。
一、聚簇索引与二级索引
主键索引(聚簇索引)
在创建表时,InnoDB引擎会根据不同场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键
- 如果没有主键,就选择第一个不包含null值的唯一列作为聚簇索引的索引键
- 如果上面两个都没有,InnoDB会生成一个隐式自增的id列作为聚簇索引的索引键
也就是说InnoDB引擎一定会创建聚簇索引。
InnoDB的索引默认采取的数据结构是B+Tree,关于B+Tree请看:Mysql为什么采用B+Tree作为索引?
二级索引(辅助索引)
聚簇索引之外的其他索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。
主键索引和二级索引默认使用的都是B+Tree索引,主键索引与二级索引的B+Tree区别在于:
- 主键索引的B+Tree存放的是实际数据,所有完整的记录都存放在主键索引的B+Tree的叶子节点中
- 二级索引的B+Tree存放的是主键值,而不是实际数据
可以发现,InnoDB在存储数据的时候,其实存储的是主键索引,数据存放在主键索引的叶子节点中,可以理解成主键索引文件。如果创建了二级索引,可以理解会生成一份新的文件来存放二级索引,二级索引不会把数据拷贝一遍,因为成本太高,所以二级索引里面存放的是主键值,如果需要数据怎么办呢?通过回表来完成:
回表:通过二级索引获得主键值,然后通过主键索引查询到主键索引的叶子节点,获取其中的整行数据,这个过程叫做回表。
回表过程会查询两次B+Tree,性能会低一些,所以实际上希望尽可能避免回表的过程,那在什么情况下不会发生回表呢?
覆盖索引
当需要查询的数据列已经被索引包含时,就不需要再去主键索引的叶子节点中获取整行的数据,这时候,就不会发生回表。
这种在二级索引的B+Tree就能查到到结果的过程就叫作覆盖索引。
当使用了覆盖索引,而不用回表时,mysql在explain查询过程的时候,extra列会显示:using index,对应的type可能是index(全索引扫描)或者range(扫描了部分索引,通过过滤条件过滤了部分索引数据)。
using index
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|----|-------------|-----------|-------|---------------|----------|---------|------|------|-------------|
| 1 | SIMPLE | employees | index | NULL | hire_date| 5 | NULL | 1000 | Using index |
using range
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|----|-------------|-----------|-------|---------------|----------|---------|------|------|--------------------------|
| 1 | SIMPLE | employees | range | hire_date | hire_date| 5 | NULL | 100 | Using where; Using index |二、联合索引
多列组合形成一个索引,称为联合索引;
联合索引的时候,例如(a, b),B+树底层的叶子节点,按照先a后b(先对a排序,a相同的情况下,按b进行排序)的原则进行排序,叶子节点里面存放的也是主键索引。
联合索引的时候,如果查询条件有多个,在经过查询优化器之后,每条查询条件筛选之后的数据必须仍是有序的,才能完整地利用联合索引中的每一列。
举例说明:联合索引(a, b, c),数据在联合索引中是按照先a、后b、再c的顺序进行排列的,所以,如果筛选出比如a = 3的之后的所有数据,这时候,b是有序的,如果再筛选出b = 4之后的所有数据,这时候,c是有序的,那么可以再筛选出1 < c < 5的所有数据,这样能充分发挥联合索引的作用,最后如果需要回表,那么不会多查一行数据。
但是如果筛选条件是b = 2 and c = 3这种,这就无法利用索引,因为b、c只是局部有序的;
如果筛选条件是a > 2 and b = 3这种,由于a的值不是一个固定值,所以b、c同样只是局部有序的;
这里我有一点疑问:
1、mysql 8.0之后,取消了缓存器的功能,原因是因为mysql缓存器命中率太低,比如说,查询结果集很大,但是因为编辑了其中某一条数据,导致整个查询结果集从内存中删除,成本太高,导致缓存的性价比不高,所以取消了mysql的缓存器。我想请教,redis不是基于同样的原理吗?redis同样也是将结果集缓存到内存中?redis在存储查询结果到缓存中时,是怎样进行缓存的,是不是它的key是查询语句或者查询语句的hash值,然后value是整个查询结果这样子?比如说有一个查询语句,缓存了1000条数据到缓存中,那么如果其中有一条数据在数据库中发生了更新,redis是不是同样需要删掉这1000条数据呢?那为什么mysql自己的缓存器删掉了,但是redis却广泛使用呢?mysql是不是能直接把redis集成进去?
2、mysql的联合索引中,对于联合索引(a, b),select * from t_table where a > 1 and b = 2,这条语句只能用上a的索引,不能用上b列的索引,但我理解,b列的索引也可以用得上?比如说对于a的扫描范围是a>1的全部数据,那是不是可以在符合a>1的所有数据里面,对于每一个不同的a取值,都在其中查找b = 2的值呢?因为b是局部有序的,所以比如说对于符合a > 1的某个a的值,例如a = 2,我在联合索引中一旦找到b = 2的值之后,那么a = 2这个情况就查找完成了,因为a = 2时,b是有序的,那么我找到a = 2时,第一条b = 2的数据之后,按照链表顺序一直找到第一条b > 2的数据,那么在这之后的数据将是a = 2,但b > 2的情况,都不符合条件,这算不算用上b列的索引呢?这和SELECT * FROM t_user WHERE name like ‘j%’ and age = 22,这条查询语句的情况是不是类似的呢?就是我在每一个满足like ‘j%’的数据中,按照age是局部有序的这一特点,去查找每一个局部,尽可能减少扫描的范围,那么是不是可以认为select * from t_table where a > 1 and b = 2这条语句中,a列和b列的索引都用上了呢?
索引下推
mysql5.6之后,引入索引下推优化,我理解这是本来就应该有的功能,不能算是什么优化。
上面提到过,select * from t_table where a > 1 and b = 2的情况下,mysql是不会用到b列的索引的,所以实际上mysql只用到了a列的索引,那么旧版本的mysql做法是,把符合a > 1条件的所有主键都找到,然后去主键索引里面回表,然后把完整的数据记录返回给server层,再由server层去判断是否满足查询条件,如果不满足过滤掉,满足返回给客户端。
这明显是不合理的,因为索引里面明显是有b列的数据的,所以实际上我通过索引,能判断出来,哪些记录(用主键来描述)是肯定不符合查询条件的,把这些记录过滤掉,这样可以减少回表的记录数量,减少返回给server层的数据量。
索引下推指的是在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
三、索引的使用场景
索引是要付出一定代价的,如下:
- 索引占用磁盘的物理空间,数量越大,占用空间越大
- 创建和维护索引需要时间,这种时间随着数据量的增加而增加
- 会降低表的增改删效率,因为每次增改删数据,B+树为了维护索引的有序性,需要进行动态维护
适合使用索引的场景
- 对于唯一性的字段,例如商品的编码
- 经常用于where查询条件的字段,这样可以提高整个表的查询速度,如果查询条件不止一个字段,可以考虑建立联合索引
- 经常用于group by和order by的字段,这样在查询的时候,就不用再做额外的排序了
不适合使用索引的场景
- where、group by和order by中用不到的字段,索引的作用是定位,起不到定位作用的字段,一般不需要创建索引
- 字段中存在大量重复的数据,例如对于性别字段,只有男女,过滤记录的效率太低了
- 表中数据很少,不需要创建索引,全表扫描也很快
- 经常更新的字段,因为索引字段的更改,需要频繁地重建索引,会影响数据库性能
四、优化索引的方法
1、防止索引失效
索引失效的情况:
- 左模糊匹配或者左右模糊匹配,like %xx或者like %xx%
- 查询条件中对索引列做了计算、函数、类型转换操作,会引起索引失效
- 联合索引要遵循最左匹配原则,否则索引会失效
- where子句中,如果or前的条件列是索引列,or后的条件列不是索引列,那么索引会失效
2、合理使用联合索引
原因一:比如查询条件中存在order by a, b,这时候可以建立联合索引(a, b),这样在查询的时候,就不用再次排序了
原因二:借助联合索引,如果查询语句只需要用到表格中某几列,例如只需要查询a列和b列的数据,那么可以建立联合索引(a, b),这样通过索引就可以查到数据,并将结果返回,不用再回表,减少了大量的IO操作,可以提升效率。
同理,联合索引的索引下推功能,也能借助索引,过滤掉部分不需要的记录,从而减少回表的数据量,提升查询效率。
3、主键索引设置为自增
每当插入新的数据时,数据库会根据主键将其插入到对应的叶子节点中。
如果使用自增主键,那么每次插入的新数据就会插到最后一个叶子节点后面,如果所在的数据页满了,就会开辟一个新的页面。这样每次插入一条新的数据,都是追加操作,不需要重新移动数据,效率比较高。
如果使用非自增主键,由于每次插入数据的索引值都是随机的,就有可能插入到现有数据页中间的某个位置,这将不得不移动其他数据来满足新数据的插入,这种情况称之为页分裂。页分裂可能造成大量内存碎片,导致索引结构排列不紧凑,从而影响查询效率。
4、索引设置为非NULL
原因一:索引列存在NULL会导致优化器在做索引选择的时候更加复杂,更加难以优化,因为可为null的列会使索引、索引统计和值比较都更复杂,比如进行索引统计时,count会省略值为null的行。
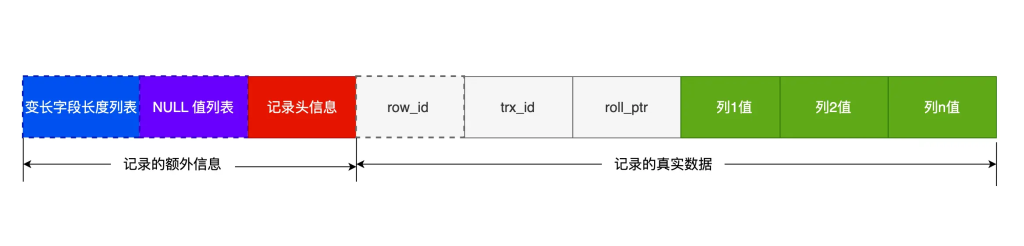
原因二:null值是一个没意义的值,但是它会占用物理空间,所以会带来存储空间的问题,因为InnoDB存储记录的时候,如果表中存在允许为null的字段,那么行格式中至少会用1字节空间存储null值列表,如下图中的紫色部分
5、使用前缀索引
使用前缀索引,可以减少索引的大小,比如某个字符串类型的字段,可能数据很大,这时候,使用前缀索引,就可以很大程度上减小索引的大小。
但是前缀索引也有一定的局限性:
- 索引中没有完全按照列来进行排序,只是根据列的前缀进行了排序,所以order by无法使用前缀索引
- 索引中没有包含完整的列的数据,所以不能将前缀索引用作覆盖索引







